

Data Processing Evolution: ETL vs ELT- Which One Suits Your Business Needs?
A Comparative Study of ETL and ELT

If you’re reading this, chances are you’re trying to figure out which approach is best for your organization’s data pipeline. And let me tell you, it’s a tricky decision to make. But don’t worry, by the end of this article, my hope is that you’d be able to distinguishing ETL from ELT and be able to understand the key differences between the two.
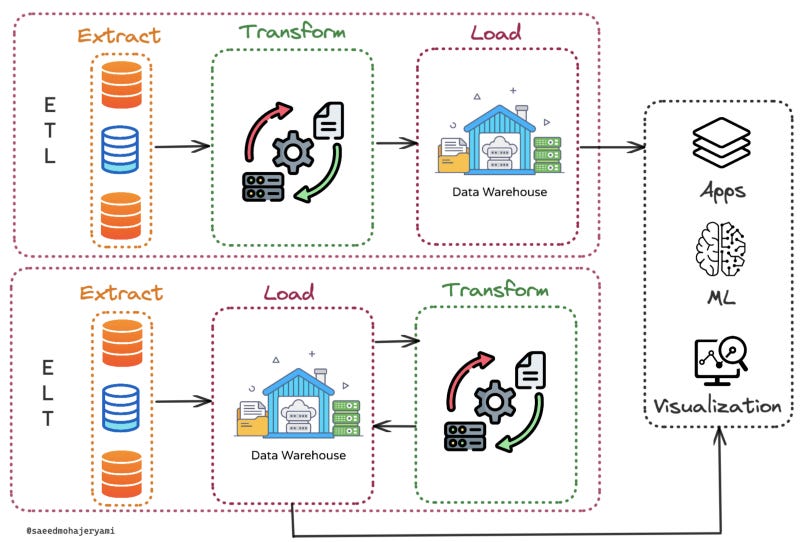
First, let’s define what we’re talking about. ETL stands for Extract, Transform, Load. It’s a process in which data is extracted from various sources, transformed to fit a specific format, and then loaded into a target system, such as a data warehouse. ELT, on the other hand, stands for Extract, Load, Transform. The main difference between the two is the order of operations. In ELT, data is loaded first and then transformed.
Now, you might be thinking, “so what’s the big deal? It’s just the order of a couple of steps.” But the truth is, the order of operations can have a huge impact on your data pipeline. ETL is great for ensuring data quality and consistency, but it can be a bit slow. ELT, on the other hand, is all about speed and scalability, but it can be a bit more risky when it comes to data consistency.
The choice between ETL and ELT is important because it can affect everything from the performance of your data warehouse to the accuracy of your analytics. It’s like choosing between a trusty old pickup truck and a fancy sports car — they both have their strengths and weaknesses, and it’s up to you to decide which one is best for your needs.
In the next sections, I am going to dive deeper into the details of ETL and ELT, including the benefits and limitations of each approach, as well as some common tools and technologies used in each. So, get ready to learn everything there is to know about ETL and ELT!
ETL (Extract, Transform, Load)
ETL is a process that has been around for quite some time and is still widely used today. In simple terms, it’s a method of moving data from one place to another and making sure it’s clean and ready for analysis.
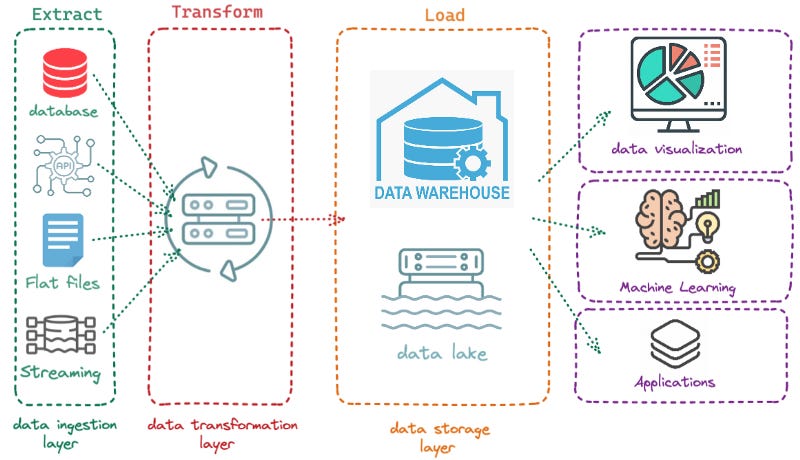
The ETL process starts with the extract phase, where data is gathered from various sources, such as databases, flat files, or web services. This data is then transformed, which is where things get really interesting. This is the phase where data is cleaned, validated, and standardized to make sure it’s consistent and ready for analysis. This can include tasks like removing duplicates, converting data types, or even running calculations.
Finally, we have the load phase, where the transformed data is loaded into its final destination, such as a data warehouse or a data lake. And voila! Your data is now ready for analysis.
Now, you might be wondering why ETL is still so popular if it sounds like a lot of work. Well, the truth is, ETL has its benefits. One of the biggest advantages is that it ensures data quality and consistency. By cleaning and standardizing data during the transform phase, you can be sure that the data you’re working with is accurate and reliable. This is especially important for organizations that rely on data for decision making.
Another benefit of ETL is that it provides a consistent and repeatable process for moving data. This makes it easy to automate and schedule data loads, which can save time and resources.
Now, no process is perfect and ETL is no exception. One of the main drawbacks of ETL is that it can be time-consuming and resource-intensive. The extract, transform, and load process can take a while, especially for large datasets. And, if you’re not careful, it can also be quite expensive in terms of hardware and software costs.
There are a variety of ETL tools available, such as Informatica, Talend, and DataStage, to mention a few. Each one has its own set of features and capabilities, so it’s important to choose the right tool for your organization’s specific needs. Some organizations set up their own ETL by running production servers and orchestrate the ETL by tools such as Airflow.
In summary, ETL is a tried and true method for moving and cleaning data. It may take a little more effort than other methods, but it can ensure data quality and consistency.
ELT (Extract, Load, Transform)
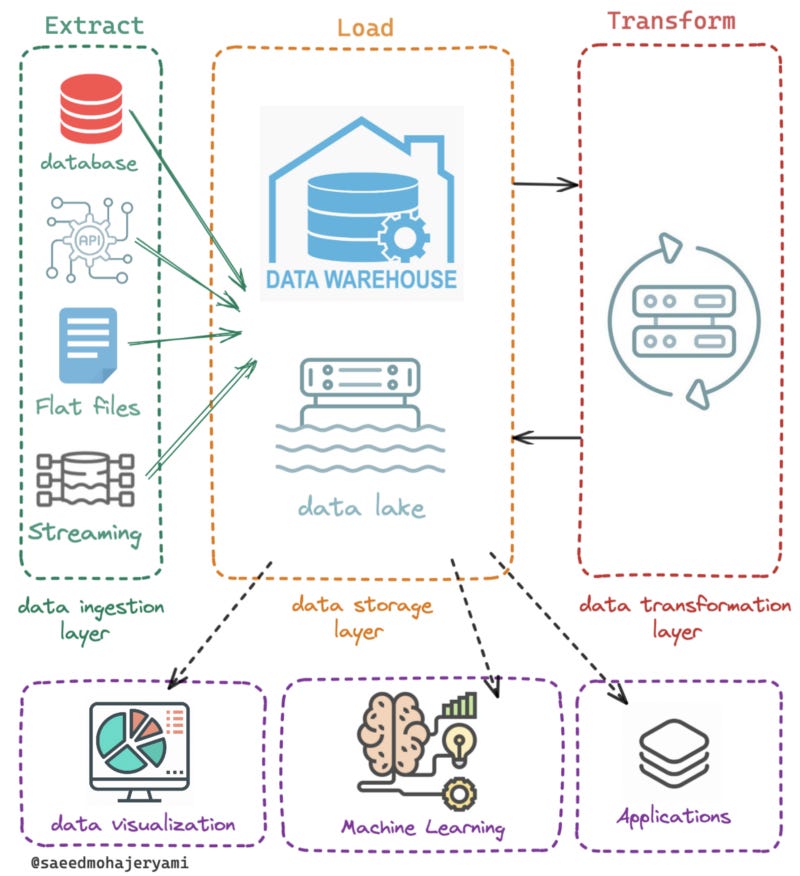
In simple terms, ELT is a data integration process that involves first loading raw data into a target system and then performing transformations on that data. This is in contrast to ETL which, as we’ve discussed, involves first extracting data, transforming it, and then loading it into a target system.
Now, you may be wondering what the big deal is with ELT. After all, both ETL and ELT seem to be doing the same thing, just in a different order. But, that’s where the magic lies. By loading the raw data into the target system first, ELT allows for the use of the target system’s own processing capabilities to perform the transformations. This can lead to some major performance and scalability benefits, especially when dealing with large volumes of data.
But, let’s not forget that ELT also has its own set of limitations. One of the main drawbacks is the lack of data quality and consistency checks that are typically performed during the extract and transform stages in ETL. This means that any issues with the data will not be caught until the transform stage, which can lead to more time and resources being spent on fixing those issues.
Speaking of resources, ELT also requires a more powerful and scalable target system. This can be a pro or a con depending on your organization’s infrastructure and budget. But, if you do have the resources to handle it, ELT can be a game changer for your data pipeline.
There are many tools and technologies available for ELT such as Apache Nifi, Apache Kafka, Apache Storm etc. Moreover, many modern cloud data warehouse solutions have a very efficient and optimized data processing that became super cheap to leverage.
Comparison of ETL and ELT
Now that I explained each separately, let’s compare them side by side. First off, it’s important to note that both ETL and ELT share a common goal: to help organizations efficiently and effectively manage and analyze their data. However, the key difference between the two approaches lies in their order of operations.
On one hand, ETL is a more traditional approach that has been around for quite some time. It’s all about ensuring that data is cleaned and transformed before it’s loaded into the target system. This approach is great for ensuring data quality and consistency, as well as making sure that data is properly formatted and ready for analysis. But, it’s not always the best approach when it comes to performance and scalability. When I was working in an organization with ETL pipeline, we had a production server running a Scala code for transformation and imagine how power Scala can be and how much flexibility you would have to perform complex transformation. However, we were paying a lot of money for our servers, which was an unnecessary overhead. In this company data was the center of all products and it was worth spending all these money to have all the possible controls on the data quality.
On the other hand, ELT is a more modern approach that has been gaining popularity in recent years. It prioritizes loading data into the target system as quickly as possible, and then transforming it afterwards. This approach allows for improved performance and scalability, as data can be loaded and analyzed in near real-time. However, it does come with the potential for data inconsistencies and errors, as data is not cleaned or transformed before it’s loaded. In my current company, we are loading our data into BigQuery and it has a great internal processing engine that we leverage for processing. However, because it’s easy to load data into BigQuery, we have many different versions of the same data and the data quality is very poor.
So, what does this all mean for you and your organization? Well, it ultimately comes down to trade-offs and considerations. If data quality and consistency are your top priorities, then ETL may be the way to go. But, if you need to analyze data in near real-time and scalability is a big concern, then ELT may be the better choice.
It’s also worth mentioning that it’s not an either-or situation. It’s possible to use a hybrid approach that combines elements of both ETL and ELT. For example, you could use ELT for near real-time data analysis, but also have an ETL process in place for data cleaning and consistency checks.
Another important point is the impact of modern cloud data warehousing solutions on the decision between ETL and ELT. As these solutions become better and cheaper, many ETL shops are considering moving to the ELT design paradigm. For example, query optimization was a serious issue and organizations hesitated to perform transformations using SQL. They tended to hire data warehouse engineers to help with query optimization as the transformation expenses could easily get out of hand. But solutions like BigQuery and Snowflake started to employ advanced query optimization techniques behind the scenes to optimize even the most inefficient queries, meaning you don’t need to worry about execution costs and you only pay for the data scanned. This can alleviate many cost concerns and encourage organizations to take their processing into the data warehouse. However, regardless of how advanced these modern solutions have become in terms of scalability, flexibility, performance, and cost-effectiveness, there are still some scenarios where ETL provides better control and data quality.
Case Studies
Let me share my experience with two companies with two different pipeline design patterns. First, there was a retail giant that I was consulting, when they learned about Snowflake and the low offer price for its services, they decided to give it a shot. They implemented ELT to improve the performance and scalability of their data pipeline. The company had been using ETL for years, but as their data volume grew, they started to run into performance issues. By switching to ELT, they were able to significantly speed up the loading and processing of their data, which in turn allowed them to make better, faster business decisions. They also cut their storage expense 1/10th. That is the magic of cloud data warehousing.
Next, I was working for a healthcare organization that decided to use ETL to improve the quality and consistency of their data. The company had been playing with ELT, but they realized that they were missing important data quality checks and transformations that were needed for compliance and reporting purposes. By switching to ETL, they were able to ensure that their data was accurate, complete, and compliant.
Now, you might be thinking, “Well, that’s great and all, but how do I know which approach is right for my organization?” And that’s a great question! The truth is, there’s no one-size-fits-all answer. It really depends on your specific business needs and priorities.
If performance and scalability are your top priorities, then ELT might be the way to go. But, if data quality and compliance are more important to you, then ETL might be the better choice. It’s all about weighing the pros and cons and making an informed decision.
ELT/ETL anti-patterns
I guess now that you have seen a few real world cases that companies changed their mind about their past decisions, it’s time to discuss anti-patterns that you must consider when choosing between ETL and ELT designs:
Over-engineering: Choosing ETL when ELT would have been sufficient can lead to unnecessary complexity and higher costs.
Under-engineering: Choosing ELT when ETL would have been more appropriate can lead to poor data quality and increased maintenance costs.
Not considering the target system: Choosing ETL or ELT without considering the capabilities of the target system can lead to poor performance and increased costs.
Not considering the source system: Choosing ETL or ELT without considering the capabilities of the source system can lead to poor performance and increased costs.
Not considering the data: Choosing ETL or ELT without considering the nature and quality of the data can lead to poor data quality and increased maintenance costs.
Not considering the environment: Choosing ETL or ELT without considering the environment in which the data will be used can lead to poor performance and increased costs.
Not considering scalability: Choosing ETL or ELT without considering scalability can lead to poor performance and increased costs as the organization grows.
Not considering security: Choosing ETL or ELT without considering security can lead to data breaches and compliance issues.
It is important to understand the organization’s specific requirements and the characteristics of the data, source and target systems, and environment before choosing between ETL and ELT designs. Also, it is important to have a clear understanding of the goals and objectives of the project and the expected outcome, and ensure that the chosen approach aligns with them.
Conclusion
In conclusion, ETL and ELT are two different approaches to data warehousing and analytics, each with its own set of benefits and drawbacks.
ETL, is a traditional approach that is focused on ensuring data quality and consistency, and it is well-suited for organizations that have strict data governance requirements and need to ensure that their data is accurate and consistent. ELT, on the other hand, is a more modern approach that is focused on improving performance and scalability and allows organizations to take advantage of the processing power of their data warehouse to perform complex transformations, rather than doing them beforehand. This approach is well-suited for organizations that need to handle large amounts of data or need real-time analytics.
When it comes to choosing between ETL and ELT, it all comes down to the specific needs of your organization. If data quality and consistency are your top priorities, then ETL is the way to go. But if performance and scalability are more important to you, then ELT may be the better choice.
In addition, it’s important to note that ETL and ELT are not mutually exclusive, and many organizations use a hybrid approach that combines the best of both worlds.
References
First and foremost, I would like to give a shout out to Kimball Group’s Ralph Kimball and Margy Ross, who first introduced the concept of ETL in their 1996 book, “The Data Warehouse Toolkit.” Their work laid the foundation for the modern data warehousing industry and continues to be a valuable resource for those looking to understand the ins and outs of ETL.
Then, I’ll outline some of the books and articles that helped me to understand data warehousing better.
Building the Data Warehouse, Fifth Edition by William Inmon
Data Warehouse Design Modern Principles and Methodologies by Matteo Golfarelli, Stefano Rizzi, and Domenico Sacca
Data Warehouse Design: Modern Principles and Methodologies by Paulraj Ponniah
Data Warehousing: Design, Development, and Best Practices by Jan L. Harrington
Implementing Data Governance: A Step by Step Guide for Achieving Compliance and Data-Driven Insights (link)
Five must-read books for data engineers (here)
Data security: essential considerations for data engineers (here)
Data integrity vs. Data quality (link)
Designing a data warehouse from the ground up: Tips and Best Practices (link)
My pick for top 48 advanced database systems interview questions (link)
I hope you enjoyed reading this. If you’d like to support me as a writer consider signing up to become a Medium member. It’s just $5 a month and you get unlimited access to Medium.
Subscribe to DDIntel Here.
Visit our website here: https://www.datadriveninvestor.com
Join our network here: https://datadriveninvestor.com/collaborate