
From Hadoop to Spark: An In-Depth Look at Distributed Computing Frameworks
Big Data in Action: Use Cases and Case Studies of Distributed Computing


Welcome to my article on Big Data and Distributed Computing! In this article, I am going to dive into the world of big data and exploring how distributed computing is helping organizations make sense of it all. I would take a look at different types of distributed computing architectures, popular frameworks and technologies, and real-world examples of how companies are using big data and distributed computing to drive their businesses. And don’t worry, I am going to keep the technical jargon to a minimum and make it an enjoyable read.
First, let’s start with the definition of big data. Simply put, big data refers to extremely large and complex data sets that are difficult or impossible to process using traditional data processing techniques. These data sets can come from a variety of sources, such as social media, sensor data, and transactional data.
Now, let’s talk about distributed computing. Distributed computing refers to the use of multiple computers, or nodes, to process data in parallel. This is in contrast to traditional computing, where a single computer is used to process data sequentially.
Distributed computing is essential for big data processing because it allows for the efficient and effective processing of large data sets. By dividing data into smaller chunks and processing them simultaneously across multiple nodes, distributed computing can significantly speed up data processing and make it more scalable.
Popular distributed computing frameworks such as Hadoop and Spark are widely used for big data processing. These frameworks provide a set of tools and technologies for data storage, data processing, and data analysis, making it easy to work with big data sets.
Big Data Characteristics
This is where things start to get interesting. You see, big data isn’t just about having a lot of data. It’s about having data that has certain characteristics that make it difficult to process and analyze using traditional methods. These characteristics are often referred to as the “four Vs” — volume, variety, velocity, and veracity.

volume
This one is pretty self-explanatory. Big data is, well, big. We’re talking about data sets that are measured in terabytes, petabytes, and even exabytes. That’s a lot of data. But it’s not just the sheer size of the data that makes it difficult to work with, it’s also the complexity and diversity of the data.
variety
Big data comes in all shapes and sizes — structured data, semi-structured data, and unstructured data. Structured data is the kind of data you’re used to working with, like numbers and dates in a spreadsheet. Semi-structured data has a bit more structure, like a JSON file. And unstructured data, well, that’s anything that doesn’t fit into the other categories — think text, images, videos, and audio. Each of these types of data requires different methods for processing and analysis.
velocity
Big data is often generated and collected at a high rate, in real-time or near real-time. This can make it difficult to keep up with the data, let alone process and analyze it. Think about the millions of tweets, Instagram posts, and Facebook updates that are generated every day. That’s a lot of data to process in real-time!
veracity
This one is all about the quality of the data. Big data is often dirty, incomplete, and inconsistent. It may be missing values, have typos, or have conflicting information. This can make it difficult to trust the data, let alone use it for analysis.
So there you have it, the four Vs of big data — volume, variety, velocity, and veracity. Each one of these characteristics can make big data a bit of a pain to work with, but with the right tools and techniques, it’s definitely doable.
Distributed Computing Architecture
First, let’s start by defining what I mean by “distributed computing architecture.” Essentially, it refers to the way that different computers, or “nodes,” work together to process data. There are a few different types of architectures that are commonly used, including:
Master-slave: This architecture is pretty self-explanatory — one node, the “master,” is in charge of coordinating the work of the other nodes, or “slaves.” This architecture is often used in batch processing, where a large amount of data is processed all at once.
Peer-to-peer: In this architecture, all nodes are equal and can communicate with each other directly. This is often used in stream processing, where data is processed as it is generated in real-time.
Hybrid: As the name suggests, this architecture combines elements of both master-slave and peer-to-peer architectures. This is becoming increasingly popular as more and more organizations look to process both batch and stream data.
Now, let’s talk about some of the most popular distributed computing frameworks that are used to implement these architectures.
Hadoop: This is probably the most well-known distributed computing framework. It’s an open-source project that was developed by the Apache Software Foundation and is based on the MapReduce programming model. Hadoop is often used for batch processing of large amounts of data.
Spark: Spark is another open-source distributed computing framework that is based on the Resilient Distributed Datasets (RDD) programming model. It’s designed to be faster and more flexible than Hadoop, and it’s often used for both batch and stream processing.
Flink: This is an open-source distributed computing framework that is specifically designed for stream processing. It’s gaining popularity because of its ability to handle both batch and stream data, and its ability to process data in real-time.
Storm: Storm is a distributed real-time computation system. It is simple, can be used with any programming language, and is a good fit for real-time processing use cases such as analytics, online machine learning, real-time dashboards and more.
These are just a few examples of the many distributed computing frameworks available. Each has its own strengths and weaknesses, so it’s important to choose the one that best fits your organization’s specific needs.
Here, let me also share some knowledge about fault tolerance and consistency and also networking protocols and topologies of distributed systems. Fault tolerance and consistency models are essential for ensuring the stability and availability of distributed systems. Fault tolerance is the ability of a system to continue functioning even when one or more of its components fail. Consistency models are used to ensure that data remains consistent across different parts of a distributed system. Some of the commonly used consistency models are Strong consistency, Weak consistency, and Eventual consistency. Both Hadoop and Spark are very strong and solid in terms of fault tolerance and consistency.
Networking protocols are used to communicate between computers in a distributed system. Some of the commonly used networking protocols are TCP/IP, HTTP, and FTP. Network topologies refer to the layout of the connections between computers in a distributed system. Some of the common topologies are star, ring, and mesh. Both Hadoop and Spark use all these configurations for different use cases.
As you can see, there are many different ways to approach distributed computing, and each has its own set of trade-offs. In the next section, I dive deeper into the data storage and management aspects of big data processing.
Data Storage and Management
Lest start with distributed file systems first. They are file systems that are spread out over multiple machines, as opposed to being stored on just one. One of the most popular distributed file systems is HDFS (Hadoop Distributed File System). HDFS is designed to store and manage large amounts of data, and it’s a critical component of the Hadoop ecosystem. But HDFS is not the only option, there are other distributed file systems such as GlusterFS and MapR-FS.

Next up, we have NoSQL databases. These databases are designed to handle the massive amount of data that comes with big data, and they’re a great option for storing and managing data in a distributed computing environment. Some popular NoSQL databases for big data include HBase, Cassandra, and MongoDB. Each one has its own strengths and weaknesses, so it’s important to choose the right one for your specific use case.

Next, we can talk about distributed object storage services. They store data as objects, which consist of a file and metadata that describes the file. Objects are stored across multiple servers in a data center and are automatically replicated to ensure durability and high availability. One example is AWS S3. The distributed object storage services can be used as a storage layer for a distributed file systems like HDFS.
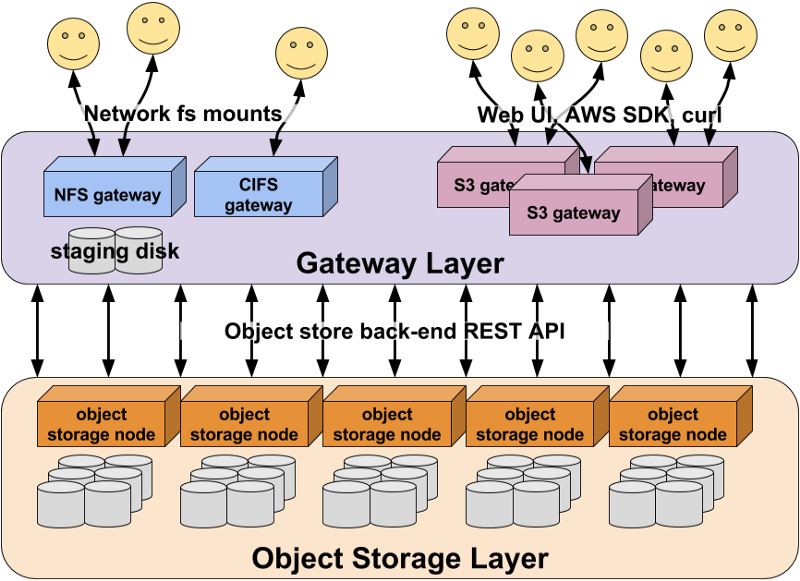
Finally, we have data warehousing and OLAP (Online Analytical Processing) for big data. These technologies are used to store, manage, and analyze large amounts of data. They allow you to perform complex queries and analysis on your data, and they’re a great option for organizations that need to make sense of large amounts of data.

Data Processing
In this section, I’m going to go through different data processings and explain each one in detail separately.
batch processing
One of the most commonly used techniques for big data batch processing is MapReduce. This programming model, developed by Google, allows for the parallel processing of large datasets. The idea behind MapReduce is to split the data into smaller chunks, called “splits,” and then process each split in parallel using a “map” function. The results from the map function are then passed to a “reduce” function, which combines the results from the map function to produce the final output.
stream processing
With the rise of IoT and the need for real-time data processing, stream processing has become increasingly important. Streaming data is data that is generated in real-time and needs to be processed in near real-time. Some popular stream processing frameworks include Kafka, Storm, and Flink. These frameworks provide the ability to process data streams in real-time and perform tasks such as filtering, aggregation, and alerting.

machine learning and deep learning
Distributed computing also plays a vital role in ML and deep learning on big data. With the explosion of data, traditional ML algorithms can no longer handle the volume, velocity, and variety of data. To tackle this problem, distributed computing frameworks like Hadoop and Spark are used to distribute the data and computation across a cluster of machines, making it possible to train models on large datasets.
In short, big data and distributed computing go hand in hand when it comes to data processing. Batch processing and stream processing are two important techniques that allow us to process large amounts of data in parallel, while machine learning and deep learning on big data is the future of data processing.
Data Security and Governance
This section is about the security and governance of big data in the context of distributed computing. This is an important topic because as data gets bigger and more distributed, the risks of data breaches and non-compliance also increase. Big data comes with its own security challenges. Let’s start by discussing these challenges first. With the sheer volume and variety of data being collected and stored, securing this data can be a daunting task. This is especially true when dealing with sensitive information such as personal data and financial transactions.
But there are a number of strategies and tools that can be used to keep your big data secure. Encryption is one of the most effective ways to protect your data from unauthorized access. By encrypting data at rest and in transit, you can ensure that even if someone does gain access to your data, they won’t be able to read it without the appropriate decryption key.
Authentication and access control are also crucial for protecting your big data. By implementing strong authentication and access control mechanisms, you can ensure that only authorized users are able to access your data. This can be done through the use of user accounts, roles, and permissions.
Now, let’s talk about data governance. This is the process of ensuring that your data is accurate, complete, and compliant with regulations and laws. This can include things like data quality checks, data lineage tracking, and data retention policies.
One important aspect of data governance is data lineage. This is the process of tracking the origin of data, how it is transformed, and where it ends up. By understanding the lineage of your data, you can identify issues and improve the overall quality of your data.
Another important aspect of data governance is data retention. This is the process of determining how long data should be kept and when it should be deleted. This is crucial for compliance with regulations and laws, as well as for maintaining the integrity of your data.
In short, big data security and governance is all about ensuring that your data is protected and that it is being used in an appropriate and compliant manner. By implementing encryption, authentication, and access control, and by keeping a close eye on data lineage and retention, you can keep your big data secure and compliant.
Case Studies and Use Cases
Let’s explore some real-world examples of how companies and organizations are using big data and distributed computing to drive their businesses.
One example is in the retail industry, where online retailers use big data and distributed computing to track customer behavior and preferences. By analyzing data from customer interactions on their website, retailers can identify which products are most popular, and tailor their marketing campaigns to target specific segments of their customer base. Two examples of these retail giants are Amazon and Shopify who collect their global customers’ data to make real time optimizations on price and marketing.
Another example is in the healthcare industry, where hospitals use big data and distributed computing to analyze patient data and improve the efficiency of their operations. By analyzing data from electronic health records and other sources, hospitals can identify patterns in patient treatment and outcomes, and develop more effective treatment protocols.
In the finance sector, companies such as banks use big data and distributed computing to detect and prevent fraud. By analyzing large amounts of data from transactions and customer interactions, they can identify patterns that indicate fraudulent activity.
These are just a few examples, but the possibilities are endless. With the help of distributed computing, big data is being used to improve operations, gain insights, and make data-driven decisions in all sorts of industries.
In conclusion, the use cases of big data and distributed computing are not only limited to the above examples but also it has the potential to revolutionize many areas of our lives. It’s exciting to see how companies and organizations are using big data and distributed computing to drive their businesses and make a positive impact on our world.
Best Practices in Big Data Processing and Distributed Computing
First off, when it comes to big data, it’s important to remember these 3 V’s: volume, velocity, and variety. You need to have the right infrastructure in place to handle the sheer amount of data you’re working with, be able to process it quickly, and be able to handle the various types of data you’re dealing with. One of the best ways to do this is by using a distributed computing framework like Apache Hadoop or Apache Spark. These frameworks allow you to easily scale your computing power and storage capacity, making it easier to handle large amounts of data.
Another important aspect of working with big data is data management. You need to be able to store, organize, and access your data easily and efficiently. One great way to do this is by using a data lake. A data lake is a centralized repository that allows you to store all your data, structured and unstructured, at any scale. This makes it easy to access and analyze all your data in one place, without having to worry about where it’s stored or how it’s organized.
When it comes to distributed computing, one of the most important things to keep in mind is to always design your system with scalability in mind. This means that your system should be able to handle an increasing amount of data and computing power without becoming a bottleneck. One way to do this is by using a distributed architecture, where tasks are split up and distributed among multiple machines. This allows you to easily add more machines to your system as your needs grow.
Another key aspect of distributed computing is fault tolerance. With so many machines working together, it’s important to make sure that your system can handle failures gracefully. This means that if one machine goes down, the rest of the system should still be able to function without interruption. One way to do this is by using replication, where data is stored on multiple machines. This way, if one machine fails, the data is still available on other machines.
Finally, it’s important to keep monitoring and performance tuning in mind. With so many machines working together, it can be easy to miss performance bottlenecks. By monitoring your system, you can identify and fix these bottlenecks before they become a problem.
Anti-patterns in Big Data Processing and Distributed Computing
Let’s talk about the “big data hammer” first. This is when you use big data and distributed computing tools to solve problems that don’t actually require them. Sure, you might be able to store and process a ton of data with these tools, but if you’re not using that data to solve a real problem, you’re just wasting your time and resources. So, before you start using big data tools, make sure that the problem you’re trying to solve actually requires them.
Another anti-pattern to watch out for is the “data silo.” This is when you have different teams or departments using different tools and systems to store and process data, without any real coordination or communication between them. This can lead to a lot of confusion and wasted effort, as everyone is working with different versions of the same data. To avoid this, make sure that everyone is on the same page when it comes to data storage and processing, and that there is a clear plan for how data will be shared and used across the organization.
Finally, there’s the “distributed computing death spiral.” This is when you start adding more and more nodes to your distributed computing system, in the hopes of increasing performance and scalability. But, as you keep adding nodes, the complexity of the system increases, which can lead to more bugs and issues. Eventually, the system becomes so complex that it’s almost impossible to maintain and troubleshoot. To avoid this, be mindful of how many nodes you’re adding to your system, and make sure that you have a clear plan for how to manage and maintain the system as it grows.
So, there you have it — a few anti-patterns to watch out for when working with big data and distributed computing. Just remember — be mindful of what you’re trying to accomplish, keep everyone on the same page, and don’t let your system get too complex.
References
“Hadoop: The Definitive Guide” by Tom White — This book is a comprehensive guide to the Hadoop ecosystem and covers all of the major components of Hadoop, including the Hadoop Distributed File System (HDFS), MapReduce, and YARN. It also covers how to use Hadoop in real-world applications and provides best practices for performance tuning and debugging.
“Data-Intensive Text Processing with MapReduce” by Jimmy Lin and Chris Dyer — This book provides a hands-on introduction to data-intensive text processing using the MapReduce programming model. It covers the basics of text processing and provides detailed examples of how to use MapReduce to process large text corpora.
“Big Data: A Revolution That Will Transform How We Live, Work, and Think” by Viktor Mayer-Schönberger — This book provides a broad overview of big data and its potential impact on society. It covers the history of big data, the technological advances that have made it possible, and the ethical and societal implications of big data.
“Streaming Systems: The What, Where, When, and How of Large-Scale Data Processing” by Tyler Akidau, Slava Chernyak and Reuven Lax — This book provides a comprehensive overview of the field of streaming systems and covers the most important concepts and technologies. It covers the design and implementation of streaming systems, and provides a detailed look at the trade-offs involved in building them.
“Distributed Systems: Concepts and Design” by George Coulouris, Jean Dollimore, Tim Kindberg — This book provides a comprehensive introduction to the concepts and design of distributed systems. It covers the principles and practices for designing and implementing distributed systems, and provides detailed examples of how to build distributed systems using a variety of technologies.
Event-Driven Systems: A Deep Dive into Pub/Sub Architecture (link)
Edge Computing: The Future of Data Processing and Analysis (link)
Edge Computing and Machine Learning: Unlocking the Potential of Real-Time Data Analysis (link)
Designing a data warehouse from the ground up: Tips and Best Practices (link)
My pick for top 48 advanced database systems interview questions (link)
I hope you enjoyed reading this. If you’d like to support me as a writer consider signing up to become a Medium member. It’s just $5 a month and you get unlimited access to Medium.
Level Up Coding
Thanks for being a part of our community! Before you go:
👏 Clap for the story and follow the author 👉
📰 View more content in the Level Up Coding publication
🔔 Follow us: Twitter | LinkedIn | Newsletter
🚀👉 Join the Level Up talent collective and find an amazing job